Rarefaction
Arguments
- object
A \(m \times p\)
numericmatrixordata.frameof count data (absolute frequencies giving the number of individuals for each category, i.e. a contingency table). Adata.framewill be coerced to anumericmatrixviadata.matrix().- ...
Currently not used.
- sample
A length-one
numericvector giving the sub-sample size. The size of sample should be smaller than total community size.- method
A
characterstring or vector of strings specifying the index to be computed (see details). Any unambiguous substring can be given.- step
An
integergiving the increment of the sample size.
Value
A RarefactionIndex object.
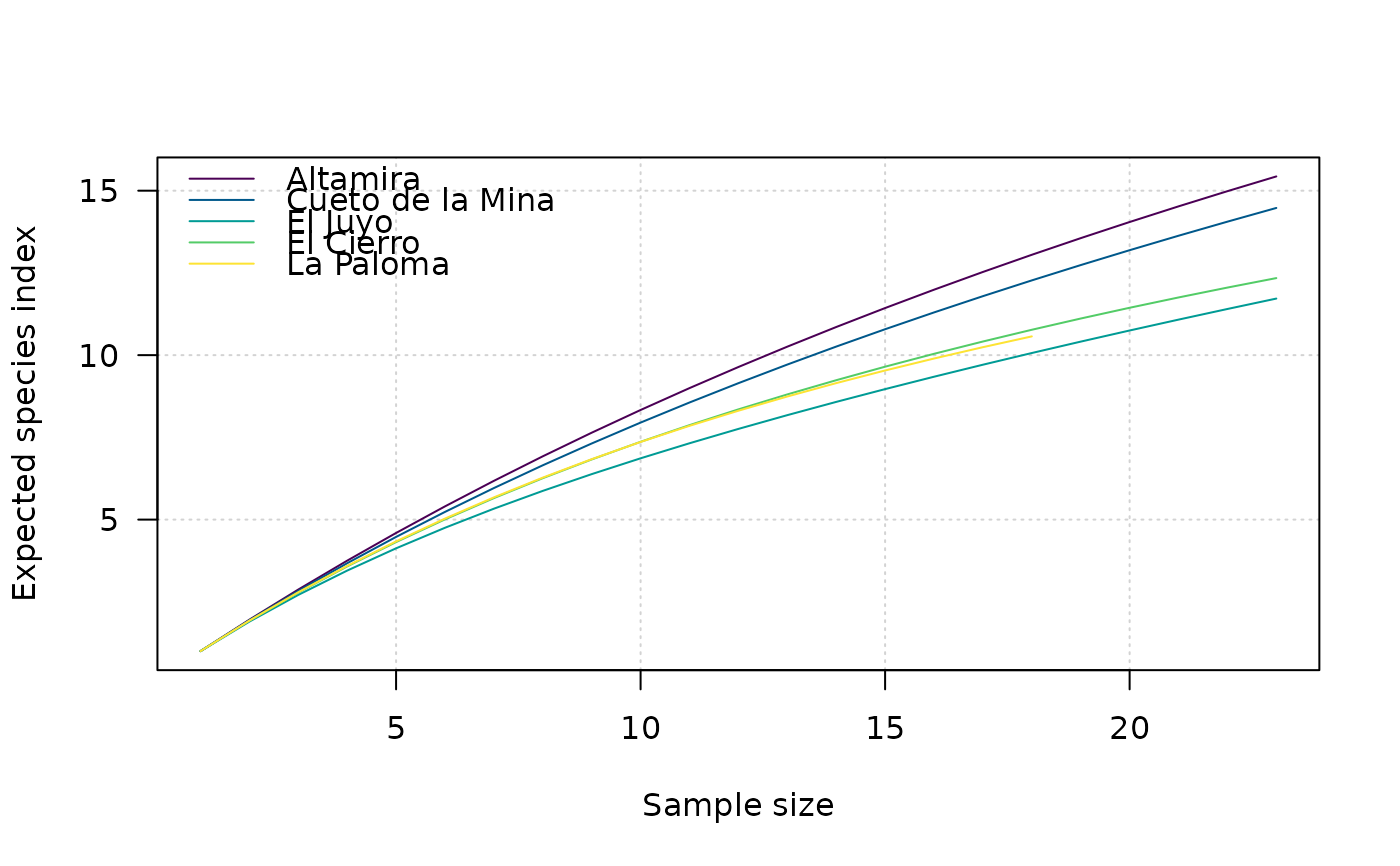
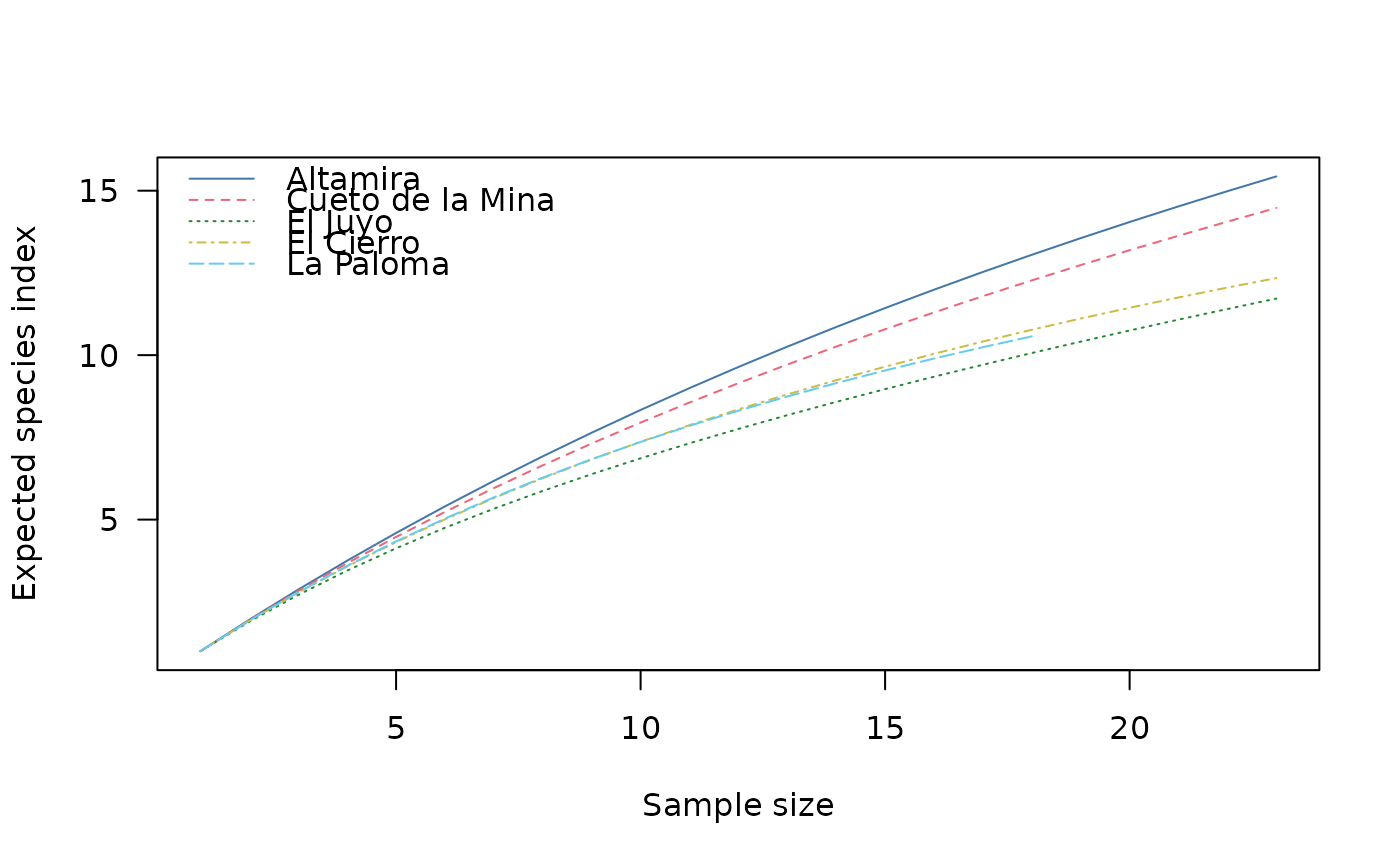
Rarefaction Measures
The following rarefaction measures are available for count data:
baxterhurlbertHurlbert's unbiased estimate of Sander's rarefaction.
Details
The number of observed taxa, provides an instantly comprehensible expression of diversity. While the number of taxa within a sample is easy to ascertain, as a term, it makes little sense: some taxa may not have been seen, or there may not be a fixed number of taxa (e.g. in an open system; Peet 1974). As an alternative, richness (\(S\)) can be used for the concept of taxa number (McIntosh 1967).
It is not always possible to ensure that all sample sizes are equal and the number of different taxa increases with sample size and sampling effort (Magurran 1988). Then, rarefaction (\(E(S)\)) is the number of taxa expected if all samples were of a standard size (i.e. taxa per fixed number of individuals). Rarefaction assumes that imbalances between taxa are due to sampling and not to differences in actual abundances.
See also
index_baxter(), index_hurlbert(), plot()
Other diversity measures:
diversity(),
evenness(),
heterogeneity(),
occurrence(),
plot.DiversityIndex(),
plot.RarefactionIndex(),
profiles(),
richness(),
she(),
similarity(),
simulate(),
turnover()